
Planning for high accessibility can assist in keeping an application or process running in spite of unfavorable conditions and adverse circumstances. But, what can you do when something so critical happens that you’ve lost data and it’s quite difficult to keep your application and processes from going down? At that point when something disastrous occurs, you want to get your services on track again. You should know your objectives, the expenses and drawbacks of your plan, and how to implement it.
What is Disaster Recovery?
Disaster Recovery is tied in with recovering from high-impact events which result in downtime and data loss. A disaster is a kind of single, significant event with an effect a lot bigger and more enduring that an application can moderate through its highly accessible portion of the design.
Hearing the word ‘disaster’ evokes thoughts of natural disasters and catastrophic events like (floods, earthquakes, storms, etc) however numerous other kinds of disasters exist too. A failed deployment or update can leave an application in an unrecognizable state. That could lead to being affected by malicious hackers who can encrypt and erase data and incur different sorts of damage that take an app disconnected or eliminates a portion of its functionalities.
No matter its cause, the best solution for such a disaster whenever it occurs is a prominent, tested disaster recovery plan and an app that effectively upholds disaster recovery practices through its design.
How to Develop a Disaster Recovery Plan?
A well-developed disaster recovery plan is a single document that includes the methods needed to recover from data loss and downtime brought by disaster and identifies who is responsible for coordinating those methodologies. Administrators ought to have the option to re-establish the application connectivity and recover the data loss after such a phenomenon.
A well-structured plan that is committed to disaster recovery is important to ensure an ideal result. The process of developing a plan will assist you to arrange a complete picture of the application. The subsequent composed steps will promote good decision-making and follow through in the panicked, turbulent result of a disaster event.
Developing a disaster recovery plan requires expert knowledge of applications workflows, data, foundation, and dependencies on it.
Risk Assessment and Process Inventory
A risk analysis that looks at the effects of various types of disasters on the application is the first stage in developing a disaster recovery strategy. The risk analysis focuses more on a disaster’s potential impact through data loss and application unavailability than on its precise nature. Examine numerous fictitious catastrophes and make an effort to be precise while imagining their impact. An earthquake that affects network connectivity and data center availability may have a different impact than a focused malicious attack that modifies code or data, for instance.
The risk assessment requirements consider every cycle that can’t manage unlimited downtime and every category of data that can’t afford an unlimited loss. At the point when a disaster that influences multiple applications parts occurs, it’s important that the plan owners can utilize it to take a complete inventory of what needs attention and how to focus on each product.
Some of them consist of a single process or grouping of data. This is yet important to note, as the application will probably be one of a larger disaster recovery plan that incorporates many applications inside the organization.
Recovery Objectives
A well-structured recovery plan needs to fulfill two important business requirements for every process done by the application:
- Recovery Time Objective (RTO): It is the maximum acceptable downtime that needs to be specified by your specifications. For instance, if the acceptable downtime is 8 hours in the event of a disaster, then your RTO is 8 hours too.
- Recovery Point Objective (RPO): It is the maximum duration of acceptable data loss. Can be measured in units of time, not volume: “30 minutes of data”, “four hours of data”, and so on. This is about limiting and recovering from data loss, not data theft.
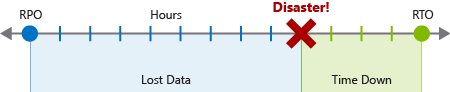
Every major process or responsibility that is executed by an application ought to have separate RTO and RPO values. Regardless of whether you arrive at similar values for different processes, each one should be produced through separate analysis which examines disaster scenario risks and potential recovery methodologies for every particular process.
The process involved with indicating an RTO and RPO is the production of disaster recovery requirements for your applications. It requires laying out the responsibility of each workload and category of data and performing a cost-benefit analysis. This includes concerns, for example, execution and support cost, functional cost, the process above, performance influence, and the impact of downtime and lost data. You’ll have to characterize exactly what “downtime” signifies for your application, and in some cases, you may lay out separate RPO and RTO values that ought to be different levels.
Determining RPO and RTO should be more than simply picking arbitrary values. A large value of the disaster recovery plan comes from the research and analysis which goes into finding the favorable impact of the disaster and the expenses of mitigating the risks.
Detailing Recovery Steps
The final one should go on to describe the steps that should be taken to restore the data loss and application connectivity. The following steps frequently incorporate information about.
- Deployments: How rollback occurs, deployments are executed, and the failure scenario for deployments.
- Data replicas: How many replications and their location? Nature and consistency characteristics of replicated data and how to change to another replica.
- Infrastructure: On-premises and cloud resources, network infrastructure, and hardware inventory.
- Backups: How often plans are created, their location, and how to restore data from them.
- Configuration and Notification: Flags and Options which could be set to gracefully degrade applications, and services used to notify the users of application impact.
- Dependencies: External applications used by applications with SLAs and contact information.
The sequential steps required typically depend on the implementation details of the application, making it essential to keep the plan updated. Regularly testing recovery plans will assist in identifying gaps and outdated sections.
Designing for Disaster Recovery
Disaster recovery is certainly not an automatic failure. This must be designed, assembled, and tested. An application that is necessary to support a solid disaster recovery method should be built from the ground up keeping in mind the disaster recovery. Azure provides services, features, and guidance to assist you with developing applications supporting disaster recovery, yet it ultimately depends on you to include them in your design.
Two main concerns in designing a disaster recovery
- Data recovery: Using backups and copying to retrieve lost data
- Process recovery: Retrieving services and deploying code to recover from the outages.
Data Recovery and Replication
Replication copies stored data between different data storage replicas. Dissimilar backup, which makes extensive, read-only snapshots of data for use in recovery, makes real-time or near-real-time copies of live data. The objective of replication is to keep replicas synchronized with as little inactivity as conceivable while keeping up with application responsiveness. Replication is a vital part of designing for high accessibility and disaster recovery and is a typical element of production-grade applications.
Replication is utilized to relieve a failed or inaccessible data store by executing a failover: changing application design to route data requests to a functioning replica. Failover is frequently automated, set off by error detection incorporated into a data storage product, or recognition that you carry out through your monitoring solution. Based on the execution and the scenario, failover may be manually executed by system administrators.
Replication isn’t something you execute from scratch. Most complete database systems and different data storage products and services incorporate some sort of replication as a firmly coordinated include because of its functional and performance requirements. However, it depends on you to include these features in your application design and use them.
The Azure Services vary in their supporting levels and concepts of replication. For example
- The capacity of Azure Storage Replication relies upon the kind of replication that is chosen for the storage account. This can be local (within a data center), zonal (between data centers within a region), or regional (between regions). Neither your application nor your administration interacts with it directly. The failovers are automatic and straightforward, and you just have to choose a replication level in terms of costs, benefits, and risks.
- Replication of Azure SQL Database is automatic at a limited scale, however, recovery from a full Azure data center or regional outage needs geo-replication. Setting up the geo-replication is manual, but it’s a top-notch service feature, and well-supported by its documentation.
- Azure Cosmos DB is a worldwide distributed database system, and replication is integral to its execution. With Azure Cosmos DB, you can configure choices connected to regions associated with your database, partitioning, and consistency of data.
Various replication designs exist which put priorities on data consistency, performance, and cost. Dynamic replication needs updates to occur on different replicas simultaneously, ensuring consistency at the expense of throughput. Conversely, passive replication performs synchronization in the background, eliminating replication as a requirement on application performance, yet expanding RPO.
Dynamic or Multi-Ace Replication empowers different replicas to be used at the same time, enabling load adjusting in cost of complicating data consistency, while dynamic replication reserves replicas for live use only during failover.

Important
Replication, as well as backup, won’t complete disaster recovery solutions on their own. Data recovery is just a single component of disaster recovery, and replication should not completely satisfy different sorts of disaster recovery scenarios. For instance, in data-corruption scenarios, the idea of the corruption might permit it to spread from the primary data store to the replicas, delivering all the replicas useless and requiring a backup for recovery.
Process Recovery
After a disaster, business data isn’t the main resource that requires recovery. Disaster scenarios will likewise commonly result in downtime, whether it’s because of network connectivity problems, data center outages, damaged VM cases, or software deployments. The application design requires you to re-establish it into a working state.
Generally, process rebuilding includes failover to a separate, working deployment. Based on the scenario, geographic location may be a critical aspect. For instance, a large-scale natural disaster that brings the entire Azure region offline will require restoring service in another region. Your application’s disaster recovery requirements, particularly RTO, ought to drive your design and assist you with concluding the number of replications you should have, where they should be located, and whether they should be maintained in the prepared state or should be ready to accept a deployment in the event of a disaster.
Based on your application design, there are perhaps a few different strategies and Azure services and features that provide an advantage to improve your application support for process recovery after a disaster.
Azure Site Recovery
Azure Site Recovery is a service committed to overseeing process recovery for workloads running on VMs deployed to Azure, VMs running on physical servers, and workloads running directly on actual servers. Site Recovery recreates workloads to substitute areas and assists you with failover when an outage occurs and upholds testing of disaster recovery plans.

Site Recovery upholds entire VMs and physical server images as well as individual workloads, where it is an entire individual application or VM or operating system with its applications. Any workload application can be repeated, yet Site Recovery has top-notch integral support for many Microsoft server applications from SQL Server and SharePoint to a handful of third-party applications like SAP.
Those applications running on VMs or physical servers should at least examine the use of Azure Site Recovery. This is a great way to discover and investigate scenarios and possibilities for process recovery.
Service-Specific Features
It is expected that you might have applications which run on Azure PaaS offerings like App Service. Most of these services offer features and guidance for supporting disaster recovery. For some specific scenarios, you can use the service-specific features for fast recovery. For instance, Geo-replication is supported by Azure SQL Server for quickly restoring service in another region. Also, Azure App Service has a backup and restore feature, and documentation incorporates guidance for using Azure Traffic Manager that helps steer traffic to the secondary region.

Testing a Disaster Recovery Plan
Designing for disaster recovery doesn’t end after you have a completed plan in hand. A vital part of disaster recovery is testing the plan to make sure that the directions and justifications are accurate and up to date.
A full-scale disaster recovery simulation should be performed every six months, but different types and scopes of tests should be performed at regular intervals, such as testing backups and failover mechanisms monthly. Always follow the processes and specifics in the plan exactly, and think about asking someone who isn’t familiar with the plan for their opinion on anything that may be made clearer. As you implement the test, identify gaps, potential improvements, and areas to automate, and add these improvements into your plan.
Verify that your testing also takes into account your monitoring system. To test that your application behaves appropriately end-to-end, including the failure detection and activation of the automatic failover, you may, for instance, introduce failures in a dependency or other several crucial components if it supports automated failover.
You will be able to decide what kinds of services you’ll need to use to achieve your recovery goals by carefully analyzing your needs and developing a plan. For you to achieve these goals, Azure offers a variety of services and features.
